
Advancements in text-to-image diffusion models have broadened extensive downstream practical applications, but such models often encounter misalignment issues between text and image. Taking the generation of a combination of two disentangled concepts as an example, say given the prompt "a tea cup of iced coke", existing models usually generate a glass cup of iced coke because the iced coke usually co-occurs with the glass cup instead of the tea one during model training. The root of such misalignment is attributed to the confusion in the latent semantic space of text-to-image diffusion models, and hence we refer to the "a tea cup of iced coke" phenomenon as Latent Concept Misalignment (LC-Mis). We leverage large language models (LLMs) to thoroughly investigate the scope of LC-Mis, and develop an automated pipeline for aligning the latent semantics of diffusion models to text prompts. Empirical assessments confirm the effectiveness of our approach, substantially reducing LC-Mis errors and enhancing the robustness and versatility of text-to-image diffusion models.
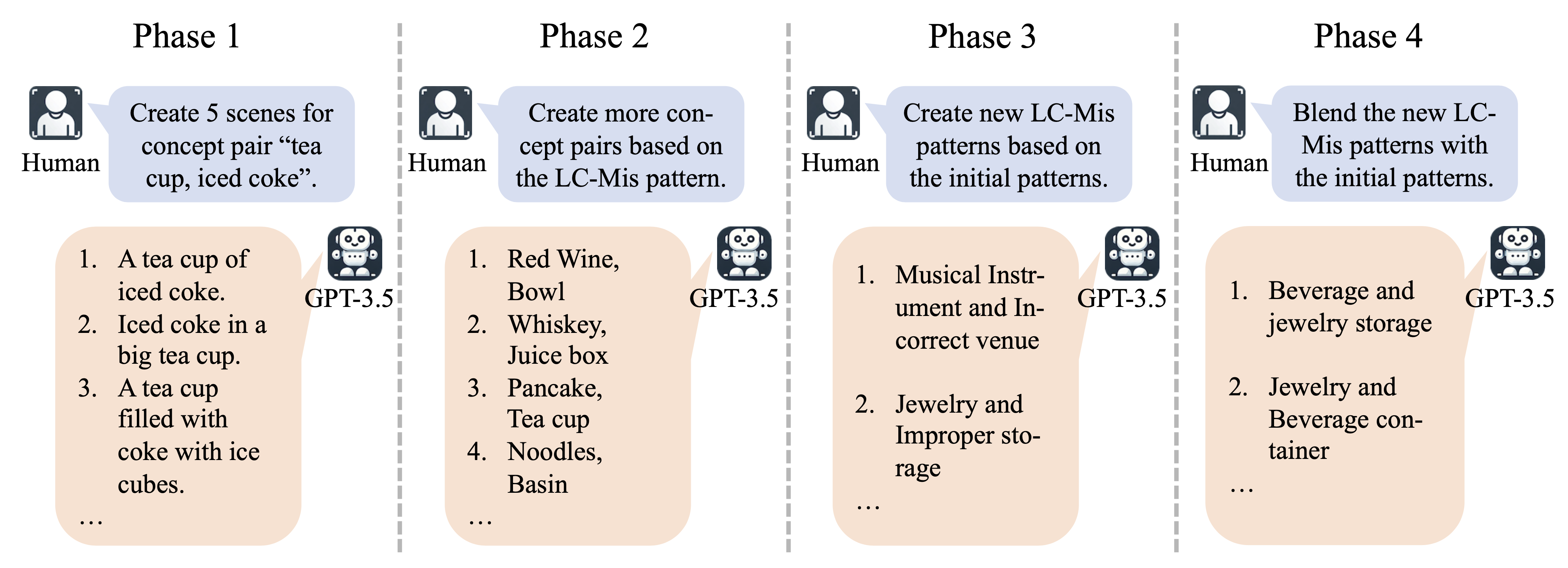
We introduce a system that utilizes the reasoning ability of LLMs to find LC-Mi concept pairs to build our dataset. In this system, LLMs generate new concept pairs, and text-to-image models generate images for evaluation, and human experts are responsible for providing instructions and evaluations.
We can iterate the phase 2 - 4 to rapidly expand our LC-Mis dataset.
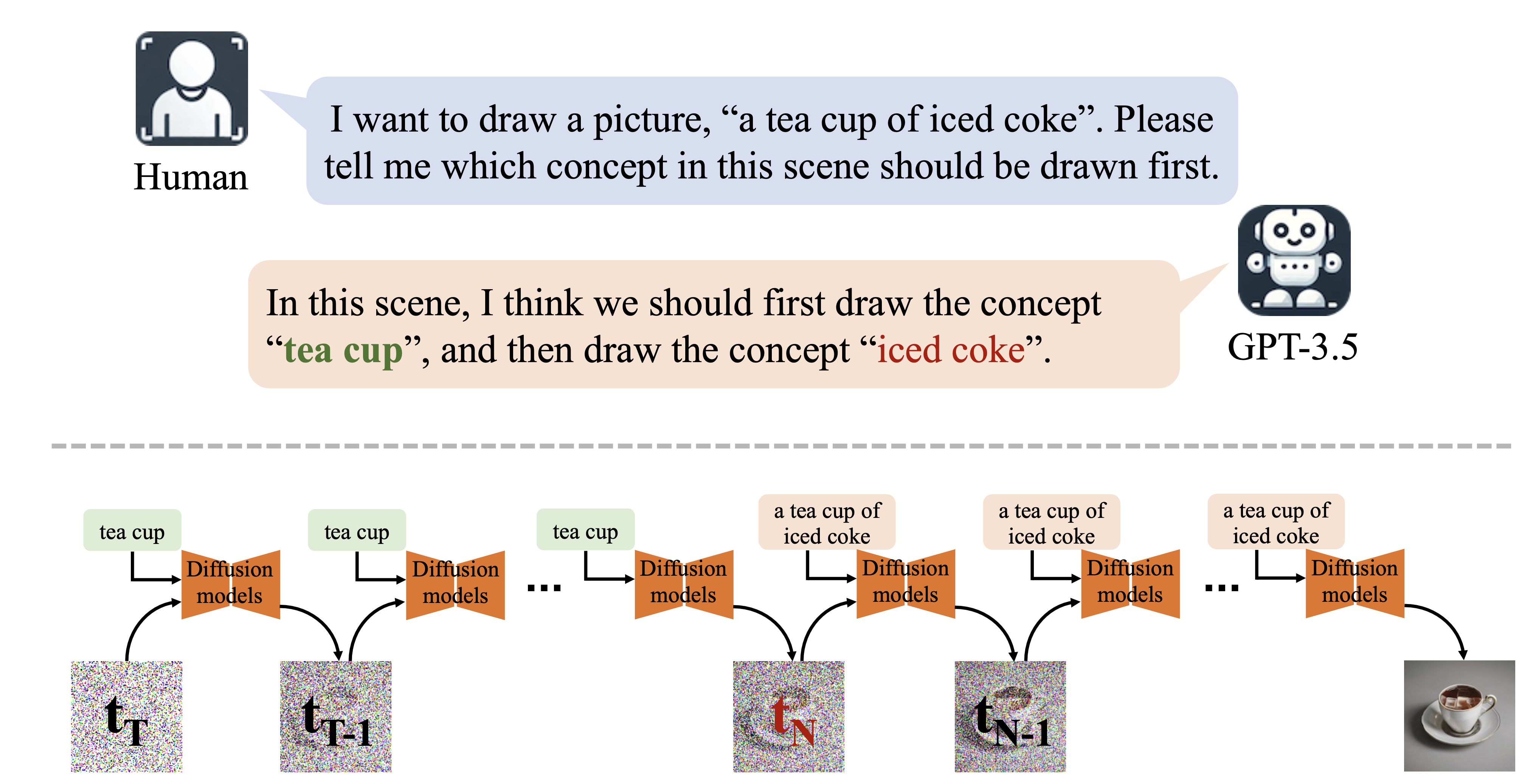
We introduce our method, Mixture of Concept Experts (MoCE). Inspired by human painting nature, we input concepts into diffusion models in sequence. Specifically, LLMs provide concepts that are easily lost to paint first. We input it separately as the text prompt to diffusion models, sample n steps, and then input the complete text prompt. Here, n is determined by a binary search algorithm.
The visualization results are as follows:

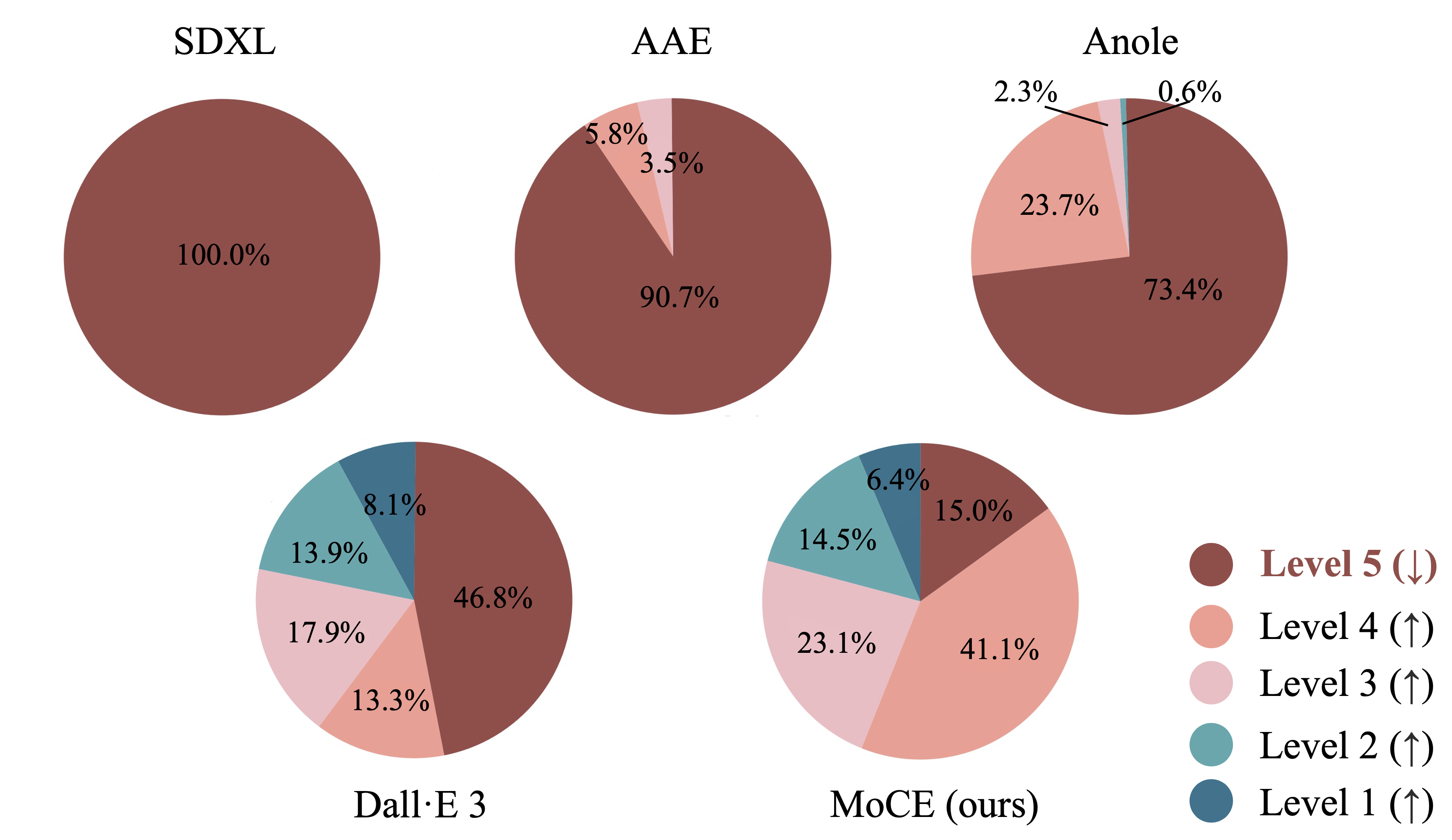
The human evaluation results are as follows. The concept pairs with the highest frequency of LC-Mis are rated as Level 5. Our MoCE significantly improves the LC-Mis issue:

We present results from the latest (available online as of July 7, 2024) Dall·E 3, Midjourney, and Stable Diffusion 3. In the example "a tea cup of iced coke", Without complex prompt engineering, models still perform poorly on the LC-Mis issue, as shown in Figure a, c and d. Complex prompt engineering from GPT-4 (Figure b) does help alleviate the issue. However, it’s important to note that this comes with significant annotation costs during Dall·E 3’s training, and is also accompanied by a certain degree of instability, highlighting the issue’s significance.
@inproceedings{zhao2024lost,
title={Lost in Translation: Latent Concept Misalignment in Text-to-Image Diffusion Models},
author={Zhao, Juntu and Deng, Junyu and Ye, Yixin and Li, Chongxuan and Deng, Zhijie and Wang, Dequan},
booktitle={ECCV},
year={2024}
}